Breaking da CAPTCHA
Автор: theShockwaveRider![theShockwaveRider ]doggy[ hackerdom ]dotty[ ru](./pictures/theShockwaveRider_mail.gif)
Intro
Для начала разберемся, о чем будем вести речь. CAPTCHA, или, если более подробно, Completely Automated Public Turing test to tell Computers and Humans Apart, - это некоторое средство или методика, позволяющая в автоматическом режиме отличать гуманоидов от компьютерных исчадий ада. Сегодня каптча, как правило, представляет из себя некоторое изображение текста с просьбой "введите символы, которые вы видите на картинке". Каптча представляет из себя одно из средств защиты от спамботов. Но стоит отметить, что, увы, со всеми плюсами, этот механизм значительно усложняет автоматизацию в том числе и легитимных действий на некоторых сайтах. А поскольку одной из благодетелей программиста, согласно Ларри Уоллу, является ленность (мы хотим, чтобы все было автоматизировано и при этом, чтобы процесс автоматизации тоже был несложен :D).
Sample code
В этой статье будет описан довольно простой подход для распознавания несложных каптч в помощь начинающим в этой области. При желании вы можете скачать демонстрационный исходник на C#, скачивая исходник, вы соглашаетесь использовать его только в образовательных целях.
Мы будем распознавать следующее изображение (см. рис. 1). Знакомство с ним у нашей команды возникло в рамках одной из проверок на безопасность одного из сайтов.

Рис. 1. Исходное изображение
And... here we go!
Каптча в своем изначальном варианте невероятно избыточна. Она весит 5880 байтов, хотя полезной для нас информации всего-то 5 байтов. Весь процесс распознавания будет заключаться в последовательном отбрасывании незначимой информации. Как говорят архитекторы: "всего лишь уберем лишнее".
Бинаризация
От чего же избавиться в первую очередь? Вот мне лично надоела цветастость этой картинки. На первом шаге необходимо произвести бинаризацию (см. рис. 2) - первичное разделение пикселей изображения на две категории: значимые пиксели и незначимые. Условимся, что значимые пиксели будут черными. В случае данной каптчи значимыми являются лишь серые пиксели, все остальные --- нет.

Рис. 2. После бинаризации
Подавление шума
Теперь озаботимся шумом. Общим подходом в его подавлении является вычисление для каждого пикселя некоторой функции и сравнение ее значения с пороговым, если значение меньше порогового, то пиксель удаляется (становится белым --- чудес не бывает), иначе остается черным. В нашем случае для каждого пикселя посчитаем число черных соседей в единичной окрестности. Соседями в единичной окрестности будем называть ближайшие восемь пикселей. Если количество черных соседей больше либо равно семи, то оставляем этот пиксель, иначе удаляем (функция killNoise). После этого удаляем все пиксели без черных соседей (функция clearNoise). После проделанных манипуляций картинка становится как на рис. 3.
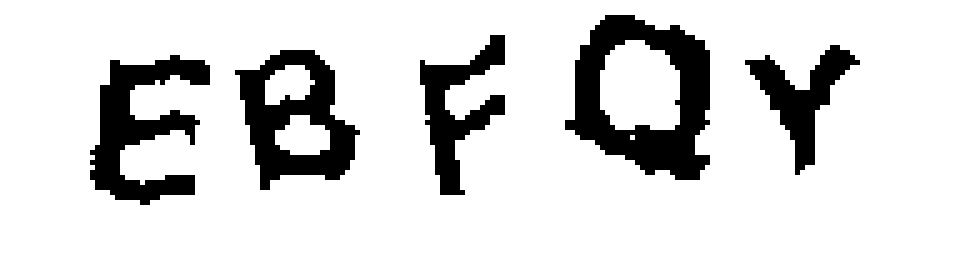
Рис. 3. После подавления шума
Выделение отдельных букв
Выглядит неплохо. Но распознавать слово целиком мы не будем, так как это значительно сложнее. Действительно, если мы распознаем произвольное пятибуквенное английское слово, то вариантов у нас 26^5, а если каждую букву в отдельности, то 26*5. Посему, выделим отдельные компоненты связности (буквы) например поиском в ширину aka BFS (функция getLetter) и будем работать с каждой по отдельности. Заметим, что у данной каптчи буквы не пересекаются, поэтому BFS сработает, иначе нам бы пришлось еще озаботиться проблемой разлучения сблизившихся букв.
Скелетизация
Что еще можно отбросить у оставшихся изображений? Их запросто можно утоньшить или провести скелетизацию --- представить в виде кривой шириной в один пиксель. С этой частью связаны приятные воспоминания о поиске методов скелетизации. Google подсказал алгоритм Зонга-Суня, который был приятно прост в реализации, но давал следующие результаты (см. рис. 4).

Рис. 4. Алгоритм Зонга-Суня
О ужас! Бедные наши букоффги! Зонг и Сунь решали наверняка несколько иные задачи... Недолго думая, было принято решение о разработке своего алгоритма (skeletonLetter). Для каждого черного пикселя проверяется несколько условий, если они выполняются, то пиксель помечается, но еще не удаляется из изображения. Помеченный пиксель для соседей по-прежнему считается черным. После того как все пиксели обработаны, помеченные удаляются, и алгоритм запускается заново. Если после очередного прохода ни одного пикселя не было удалено, то алгоритм завершается. Пиксель помечается, если выполнены следующие три условия:
- у него строго больше одного черного соседа (функция pointB)
- есть три подряд идущих белых пикселя при обходе соседей по часовой стрелке (функция point03)
- удаление этого пикселя не нарушает связности (функция checkConsistency)
Если убрать первое условие, то, когда будет уже выделен скелет, алгоритм не прекратит работу и от каждого "конца" скелета (пардон!) шаг за шагом будут продолжать съедаться пиксели, в результате не останется ни одного черного пикселя (буквы типа "О" имеют иммунитет). Второе условие отвечает за то, что пиксель является граничным, а не внутренним. Под третьим условием понимается запрет удаления крестовин, например у букв "У", "Х". Заметим, что результаты работы этого алгоритма значительно лучше (см. рис. 5).

Рис. 5. Придумки TheFire'a & theShockwaveRider'a
Масштабирование
Далее приведем полученные изображения к одному размеру (функция resize) и выпишем их матрицы. Для первой буквы имеем:
0 0 0 0 0 1 0 0 0 1 1 1 1 1 0 1 1 0 0 0 0 0 0 1 0 1 1 1 0 1 1 1 0 0 1 0 1 0 0 0 0 0 0 1 1 0 1 1 0
Но нетрудно заметить, что в результате выше описанных действий буквы O и Q, B и 8 станут неотличимыми. Поэтому добавим к этой матрице еще процент черных пикселей по отношению к размеру изображения буквы до скелетизации. Для буквы "E" в нашем случае получается 53%.
Непосредственное распознавание
Для эффективного распознавания необходимо как-либо другим образом распознать определенное количество изображений букв для создания эталонной базы, посредством сравнивания с которой и будет происходить распознавание. Для сравнения двух векторов характеристик вводят метрику. Чем меньше расстояние от одного вектора до другого, тем буквы, им соответствующие, считаются более похожими.
Вообще говоря, более перспективным методом распознавания является использование нейросетей, но пока что мы ставим перед собой цель научится распознавать каптчи методами, не требующими глубоких теоретических знаний.
Для улучшения точности распознавания можно выбрать другой вектор характеристик, учитывающих число концевых точек, крестовин. Но стоит отметить, что, как правило, при неправильном распознавании каптчи, сайты предлагают выполнить распознавание повторно. Это означает, что достаточно обеспечить некоторый стабильный процент распознавания, который может быть значительно меньше 100%. Так, например, обеспечив себе 25%, мы будем распознавать каптчу в среднем с четвертой попытки, а не с первой, это будет потеря в скорости, но не в функциональности.
Защита
Для усложнения распознаваемости каптчи рекомендуется использовать сложные преобразования букв, приводящие к их наложению и частичному смешению с фоном. Тем не менее, необходимо учитывать, что изображение, ставшее плохо распознаваемым компьютером, станет плохо распознаваемым и для человека.
Более стойкими являются смысловые каптчи с изображением формул и заданием их вычислить. Изображения объектов с просьбой написать название объекта тоже представляют интерес. Но эти подходы заведомо сужают круг возможных пользователей.